給初學者的 Python 網頁爬蟲與資料分析 (1) 前言
前言
這系列文章是與 Pycone 松果城市合作,給初學者的網頁爬蟲與資料分析教學,如果你對於 Python 有粗淺認識 (知道 Python 的資料型態, 控制結構, 寫過一些小程式), 想進一步知道要怎麼使用 Python 擷取網頁資訊並簡單做些資料分析 (如圖表、統計資料、相關性等),這系列文章可以帶你入門。一般想要寫網頁爬蟲的人,不會只想要擷取資料,他們真正想要的通常是資料分析,找出資料能提供的資訊,或使用資料驗證自己的假設,Python 也有許多資料處理與展示的好用套件可以使用 (如 NumPy, scikit-learn, pandas),這系列文章會先略過這些套件,教你直接用程式計算統計資料與畫圖,以便讓你更了解套件底層的邏輯,之後學習這些套件時會更容易上手。
步驟拆解
網頁爬蟲與資料分析可以分成以下步驟:
- 資料來源: 資料來源可以是別人整理好的資料(如政府 open data, 整理好的 csv 或 json 等文字檔), 也可以是自行從公開網頁擷取的資料 (本文會使用 PTT 網站作為範例)
- 啟動爬蟲: 如果資料不是整理好的,而是必須從公開網頁爬取,就必須利用程式與網站 server 連線取得網頁資訊 (本文會示範用 request 套件與 PTT 網站溝通)
- 資料擷取與資料淨化: 從公開網頁爬取的整個頁面,通常只有一部分是你需要的,因此要利用程式解構網頁架構,取得所需資料 (本文使用 BeautifulSoup 套件解構網頁文件,擷取所需資料); 另外,在擷取過程中或擷取後,資料通常會有些雜訊 (例如錯誤的時間格式, 英文數字混雜等),此時也要利用程式做資料淨化以便後續分析 (本文會示範利用簡單的正規表示式 regular expression 做資料過濾與淨化)
- 資料分析: 爬蟲把 raw data 爬下來之後, 你可能會想要分析資料,例如跑些統計資訊或檢查資料維度間的相關性,驗證你的假設 (本文會示範計算文章內圖片數量與推文數的相關係數)
- 資料展示: 用圖表、網頁等展示資料 (本文會示範將 PTT Beauty 版文章內的圖片存到本機端,並畫出文章內圖片數量與推文數的分佈圖)
範例程式: PTT Beauty 板今日圖片下載器
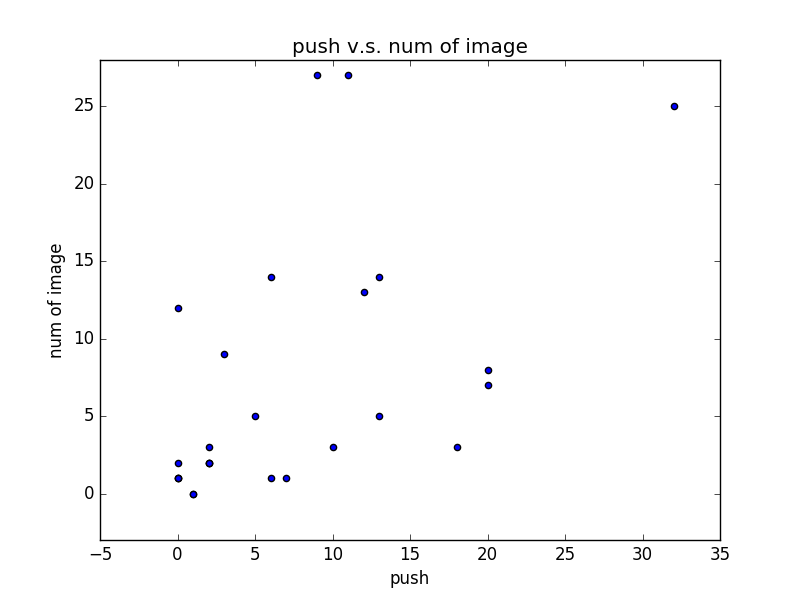
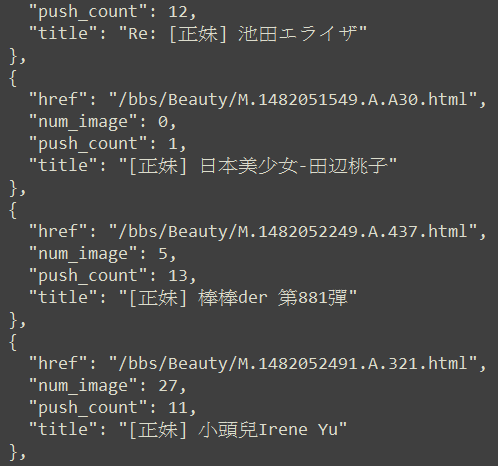
本文會教你實作一個簡單的圖片下載器,它會連上 PTT Web 版的表特板首頁,然後把今天所有文章內含的圖片下載到本機端,同時儲存各文章的標題、推文數、內含圖片數,以便後續資料分析。我們會計算圖片數與推文數的相關係數(是否張貼越多圖片的文章會得到越多推?),並畫出資料分布圖。在過程中你會學到如何用 Python 連線到網站,如何解構網頁文件並擷取、儲存資料,以及資料分析與展示的基本技巧。範例成果如下:
> python analyzer.py
推文數: [18, 20, 0, 0, 3, 6, 2, 12, 1, 13, 11, 5, 0, 20, 1, 7, 6, 2, 2, 0, 0, 32, 10, 13, 9, 2]
圖片數: [3, 7, 1, 12, 9, 1, 2, 13, 0, 5, 27, 5, 1, 8, 0, 1, 14, 2, 3, 2, 1, 25, 3, 14, 27, 2]
相關係數: 0.5259