hahow 課程爬蟲與簡單定價分析
本文講解兩件事:
- 如何爬取 hahow 所有已開課課程資料
- 計算募資價/上線價/課程長度/學生數的統計資料 (平均值),及前三者與學生數的相關性 (是否定價越低/長度越長則學生數越多?)
Pycone 松果城市 (網站, 粉絲頁) 是致力於對初學者友善的 Python 教學團隊,除了已經開的初心者課程與爬蟲課程外,陸續還有新課程在籌備中。而一門課的定價該怎麼定,大家往往有不同的意見,有人認為技術有價,不能破壞行情,且越少見的課應該越貴;有人認為較低定價可以吸引更多學生。與其靠經驗或直覺,不如讓數據說話!我們何不直接分析 hahow 上程式類課程的平均價格及各項係數與學生數的相關性?
爬取 hahow 所有已開課課程資料
身為一個懶人,寫爬蟲前第一件事當然是看 hahow 有沒有提供打包下載的課程資料或可存取的公開 API,簡單搜尋之後沒有收穫,只好從 hahow 的課程列表下手。在課程列表的網頁你會發現,這個網頁並不會一次回傳所有課程,而是隨著瀏覽器捲軸下拉,逐漸顯示更多課程。通常這種網頁多是透過 AJAX 與網站主機做非同步的溝通與資料傳輸,打開開發者工具瀏覽一下之後,很快找到了可能的 API
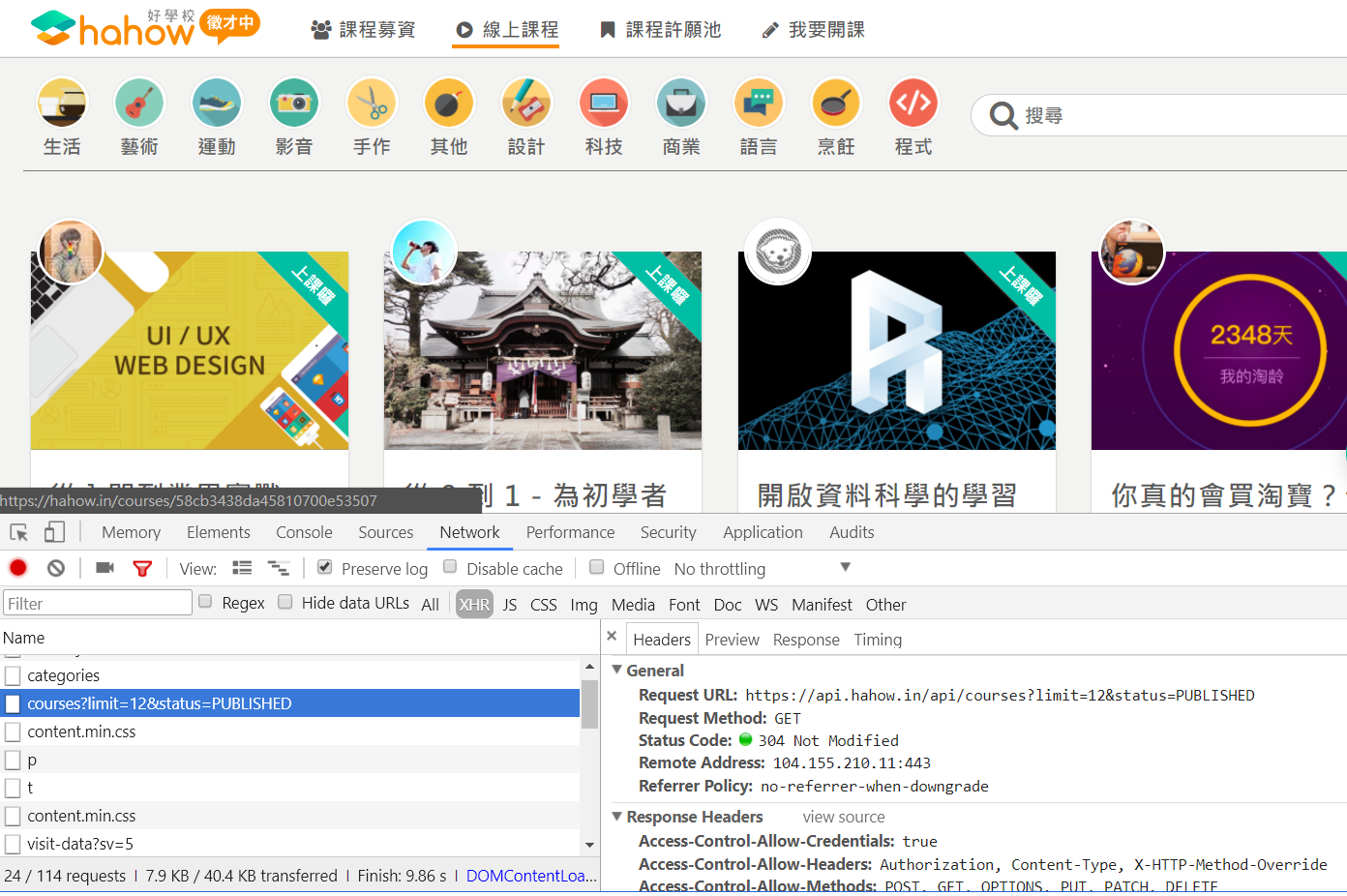
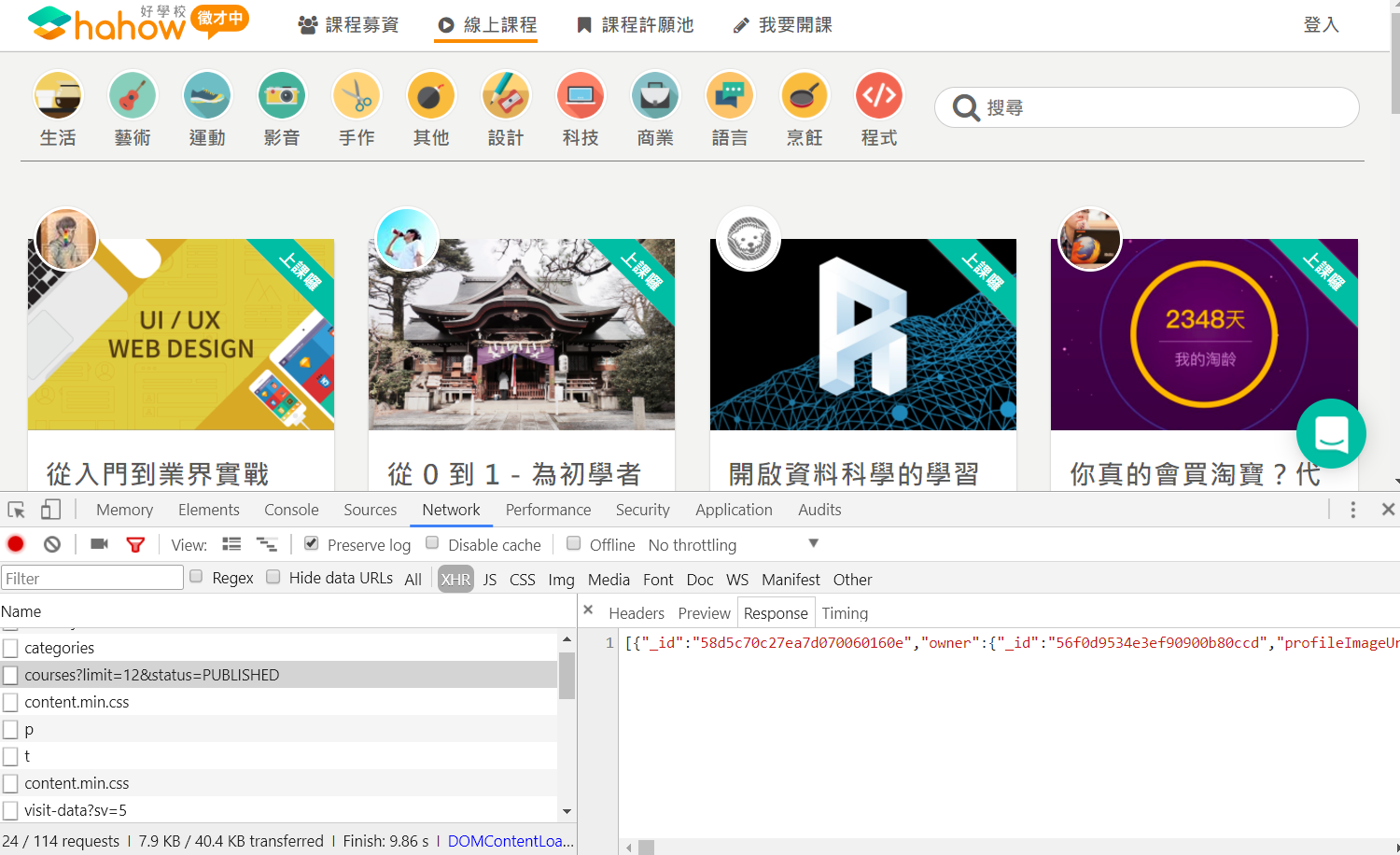
把該網址的 response 貼到 online JSON parser 驗證,果然就是課程資料
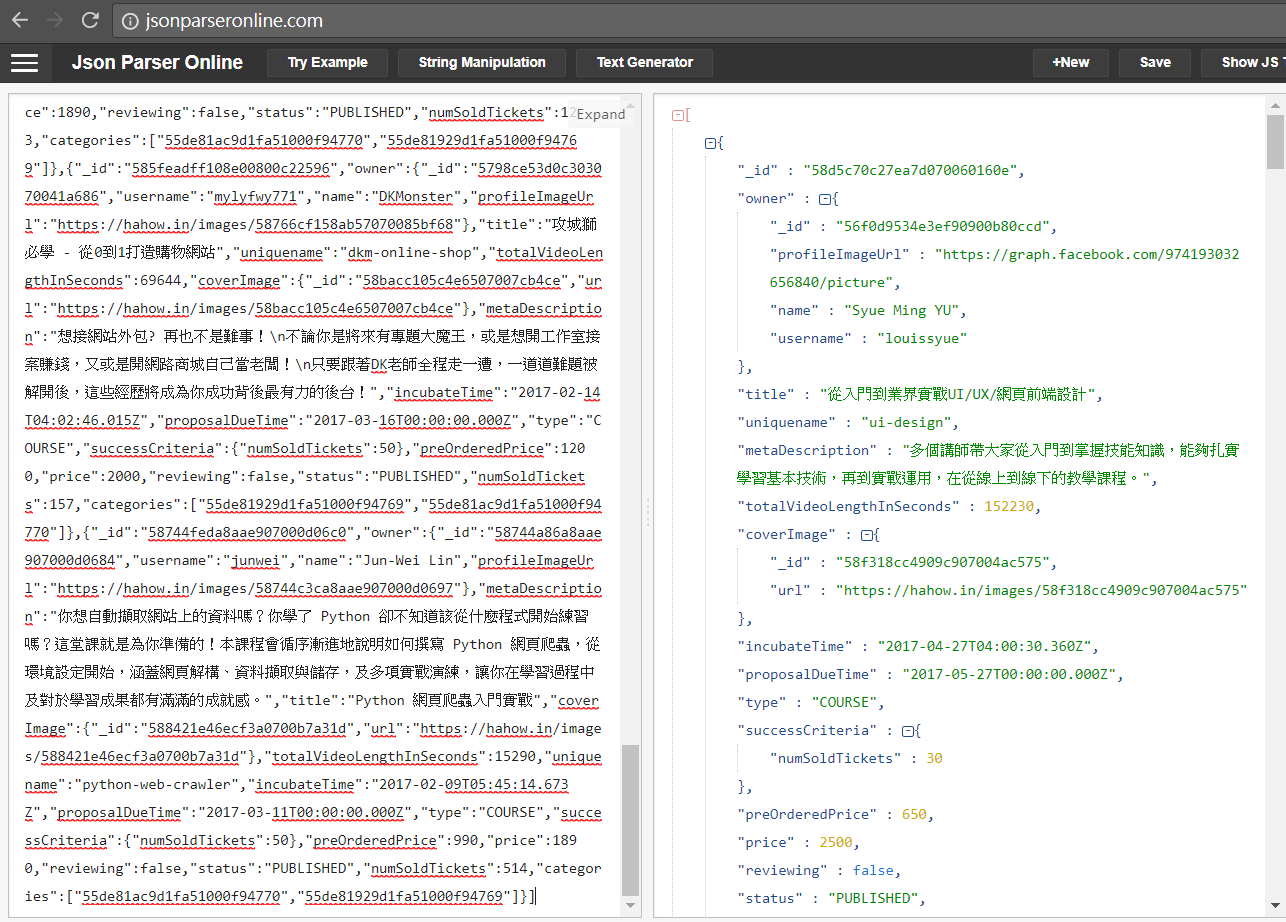
接著繼續觀察畫面捲動時是透過什麼 API 取得更多課程資訊,最後確定了:
- 一開始先透過 GET https://api.hahow.in/api/courses?limit=12&status=PUBLISHED 取得最初的 12 筆資料 (經測試一次最多可以取 30 筆)
- 接著一樣透過 GET 回傳目前最後一筆課程的 id 與募資時間,取得接下來 12 筆課程資料,直到沒有資料為止
不得不說 hahow 工程師的 API 寫得滿好的,很簡單易用 (雖然他們並沒有要給大家用 XD),因此對應的爬蟲程式邏輯也很簡單
def crawl():
# 初始 API: https://api.hahow.in/api/courses?limit=12&status=PUBLISHED
# 接續 API: https://api.hahow.in/api/courses?latestId=54d5a117065a7e0e00725ac0&latestValue=2015-03-27T15:38:27.187Z&limit=30&status=PUBLISHED
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/59.0.3071.115 Safari/537.36'}
url = 'https://api.hahow.in/api/courses'
courses = list()
resp_courses = requests.get(url + '?limit=30&status=PUBLISHED', headers=headers).json()
while resp_courses: # 有回傳資料則繼續下一輪擷取
time.sleep(3) # 放慢爬蟲速度
courses += resp_courses
param = '?latestId={0}&latestValue={1}&limit=30&status=PUBLISHED'.format(
courses[-1]['_id'], courses[-1]['incubateTime'])
resp_courses = requests.get(url + param, headers=headers).json()
# 將課程資料存下來後續分析使用
with open('hahow_courses.json', 'w', encoding='utf-8') as f:
json.dump(courses, f, indent=2, sort_keys=True, ensure_ascii=False)
return courses
將所有課程擷取下來後,我們看到每一筆課程資料內容如下:
{
"_id": "58744feda8aae907000d06c0",
"categories": [
"55de81ac9d1fa51000f94770",
"55de81929d1fa51000f94769"
],
"coverImage": {
"_id": "588421e46ecf3a0700b7a31d",
"url": "https://hahow.in/images/588421e46ecf3a0700b7a31d"
},
"incubateTime": "2017-02-09T05:45:14.673Z",
"metaDescription": "你想自動擷取網站上的資料嗎?你學了 Python 卻不知道該從什麼程式開始練習嗎?這堂課就是為你準備的!本課程會循序漸進地說明如何撰寫 Python 網頁爬蟲,從環境設定開始,涵蓋網頁解構、資料擷取與儲存,及多項實戰演練,讓你在學習過程中及對於學習成果都有滿滿的成就感。",
"numSoldTickets": 514,
"owner": {
"_id": "58744a86a8aae907000d0684",
"name": "Jun-Wei Lin",
"profileImageUrl": "https://hahow.in/images/58744c3ca8aae907000d0697",
"username": "junwei"
},
"preOrderedPrice": 990,
"price": 1890,
"proposalDueTime": "2017-03-11T00:00:00.000Z",
"reviewing": false,
"status": "PUBLISHED",
"successCriteria": {
"numSoldTickets": 50
},
"title": "Python 網頁爬蟲入門實戰",
"totalVideoLengthInSeconds": 15290,
"type": "COURSE",
"uniquename": "python-web-crawler"
}
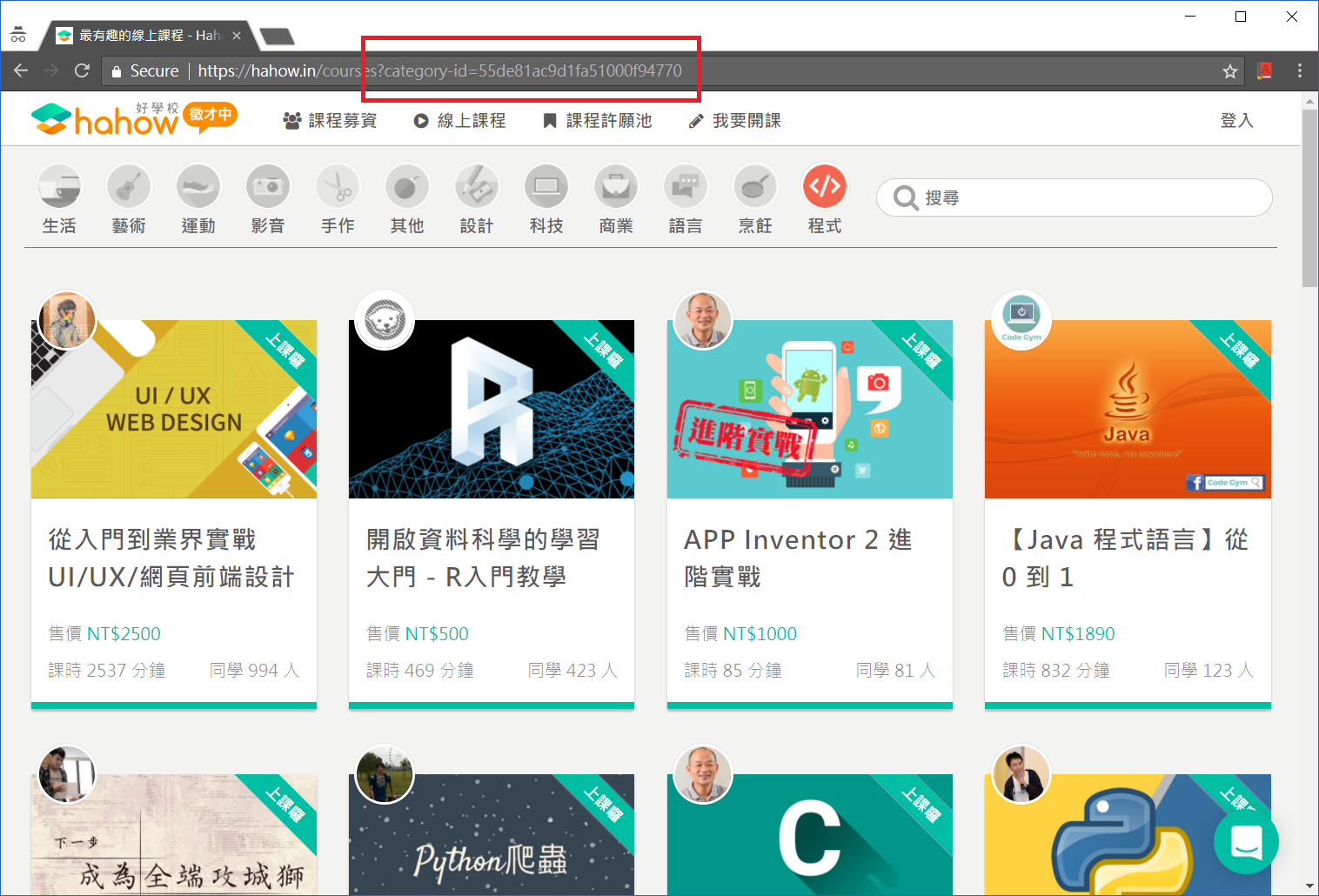
各欄位的名稱都很直覺,唯一就是課程的分類 (categories) 代碼意義不明,此時只要觀察一下各類課程的連結就可以知道代碼
計算各項係數之統計資料與相關性
收集資料是為了分析資料並進一步回答問題。我們的問題是:程式類課程的平均價格、課程長度及學生數為多少?各項係數是否與學生數有相關性?相較於之前的文章中直接寫程式計算數據,這邊我們改用 numpy 來計算,只要將感興趣的資料分別存成 list,就能夠用 numpy 直接計算統計資料
with open('hahow_courses.json', 'r', encoding='utf-8') as f:
courses = json.load(f)
# 取出程式類課程的募資價/上線價/學生數,並顯示統計資料
pre_order_prices = list()
prices = list()
tickets = list()
lengths = list()
for c in courses:
if '55de81ac9d1fa51000f94770' in c['categories']:
pre_order_prices.append(c['preOrderedPrice'])
prices.append(c['price'])
tickets.append(c['numSoldTickets'])
lengths.append(c['totalVideoLengthInSeconds'])
print('程式類課程共有 %d 堂' % len(prices)) # 23
print('平均募資價:', np.mean(pre_order_prices)) # 719.09
print('平均上線價:', np.mean(prices)) # 1322.57
print('平均學生數:', np.mean(tickets)) # 483.22
print('平均課程分鐘:', np.mean(lengths)/60) # 515.12
corrcoef = np.corrcoef([tickets, pre_order_prices, prices, lengths])
print('募資價與學生數之相關係數: ', corrcoef[0, 1]) # 0.18
print('上線價與學生數之相關係數: ', corrcoef[0, 2]) # 0.36
print('課程長度與學生數之相關係數: ', corrcoef[0, 3]) # 0.65
我們可以看到目前 23 堂程式類課程的平均募資價 (720) 與上線價 (1320),而令人意外的是募資價與學生數並沒有太大的相關性 (不是募資價越低學生就越多),反倒是課程長度與學生數呈現滿強的正相關。而我們在之前的文章已經提過,相關性並不代表因果關係,同時很明顯地,其他非數據的因素如講師名氣、文案內容、影片生動度等對於吸引學生也非常重要,因此這些數據只是幫助決策的參考資訊。
給初學者的 Python 網頁爬蟲與資料分析 (5) 資料分析及展示
這篇文章會示範簡單的統計分析 (平均值與相關係數) 與資料視覺化 (histogram 與 scatter plot),最後會淺談資料科學的三個面向作為本系列文章總結。
藉由之前的範例程式,我們已經有了今天 PTT Beauty 板所有貼文的一些資訊。假設我們想進一步認識或分析手上的數據,或對資料維度的相關性作些假設,就需要統計分析與視覺化的幫助。例如我們對貼圖數與推文數有興趣,且假設「文章內有越多貼圖會得到越多推」,第一步先將資料從 example.json 讀入之後,馬上就能得知它們的極值:
with open('example.json', 'r', encoding='utf-8') as f:
data_list = json.load(f)
images = []
pushes = []
for d in data_list:
images.append(d['num_image'])
pushes.append(d['push_count'])
print('圖片數:', images, 'Max:', max(images), 'Min:', min(images))
print('推文數:', pushes, 'Max:', max(pushes), 'Min:', min(pushes))
# 圖片數: [3, 7, 1, 12, 9, 1, 2, 13, 0, 5, 27, 5, 1, 8, 0, 1, 14, 2, 3, 2, 1, 25, 3, 14, 27, 2] Max: 27 Min: 0
# 推文數: [18, 20, 0, 0, 3, 6, 2, 12, 1, 13, 11, 5, 0, 20, 1, 7, 6, 2, 2, 0, 0, 32, 10, 13, 9, 2] Max: 32 Min: 0
平均值與相關係數
有了原始資料的 list, 平均值的計算也很容易,
def mean(x):
return sum(x) / len(x)
print('平均圖片數:', mean(images), '平均推文數:', mean(pushes))
# 平均圖片數: 7.230769230769231 平均推文數: 7.5
接著我們想知道是否「文章內有越多貼圖會得到越多推」,一個方式是計算相關係數,相關係數是共變異數 (covariance) 除以標準差 (standard deviation) 的乘積,公式可參考此處。因此,除了平均值之外,我們還需要計算偏差值 (deviation), 變異數 (variance) 與內積 (dot) 的函式
def de_mean(x):
x_bar = mean(x)
return [x_i - x_bar for x_i in x]
def variance(x):
deviations = de_mean(x)
variance_x = 0
for d in deviations:
variance_x += d**2
variance_x /= len(x)
return variance_x
def dot(x, y):
dot_product = sum(v_i * w_i for v_i, w_i in zip(x, y))
dot_product /= (len(x))
return dot_product
有了相關函式後,相關係數可依公式計算
def correlation(x, y):
variance_x = variance(x)
variance_y = variance(y)
sd_x = math.sqrt(variance_x)
sd_y = math.sqrt(variance_y)
dot_xy = dot(de_mean(x), de_mean(y))
return dot_xy/(sd_x*sd_y)
print('相關係數:', correlation(images, pushes))
# 相關係數: 0.5258449106844523
相關係數是 -1 到 1 之間的值,越接近 1 代表兩個維度越接近線性正相關,反之則為線性負相關。這個例子中的 0.5258 代表一定程度的正相關,看到這邊你一定有疑問:推文數怎麼可能被貼圖數決定?難道我貼一堆海綿寶寶圖也會被推爆嗎?當然不可能,而這個例子也引出了你可能聽過的說法:相關不代表因果 (correlation is not causation)。事實上,我們解讀相關係數時必須多方考慮,如果 x 與 y 高度正相關,可能代表:
- x 導致 y
- y 導致 x
- x, y 互為因果
- 另有他因 z 導致 x, y (例如高 GDP 同時導致高平均壽命與高基礎網路頻寬,平均壽命與基礎網路頻寬並沒有因果關係)
- x, y 根本無關,只是巧合 (例如一個地區的手機銷售量與律師人數?)
資料視覺化
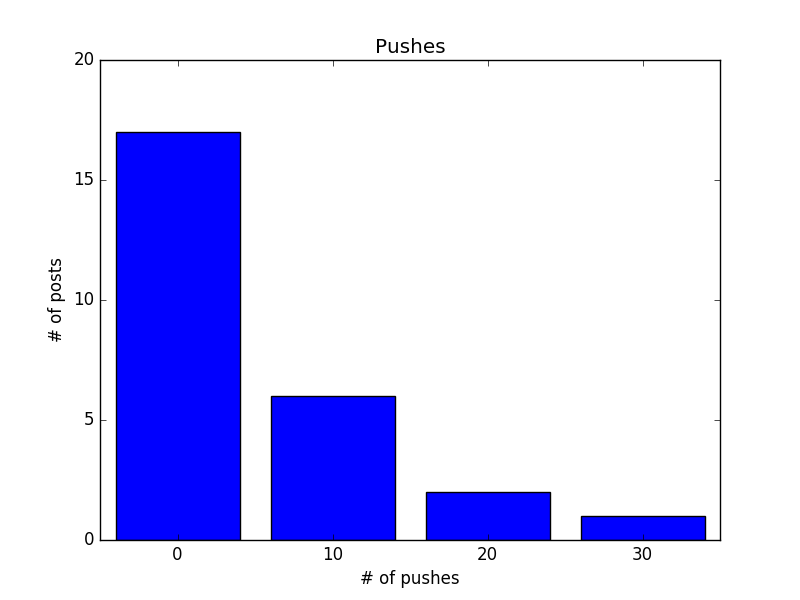
除了直接計算統計數據,將資料視覺化也是幫助我們認識資料的好辦法,例如我想知道推文數的分布,可以試著畫出 histogram, 把小於 10 推, 20 推, 30 推的文章數量以條狀圖顯示
def decile(num): # 將數字十分位化
return (num // 10) * 10
from collections import Counter
histogram = Counter(decile(push) for push in pushes)
print(histogram)
# Counter({0: 17, 10: 6, 20: 2, 30: 1})
# 畫出 histogram
from matplotlib import pyplot as plt
plt.bar([x-4 for x in histogram.keys()], histogram.values(), 8)
plt.axis([-5, 35, 0, 20])
plt.title('Pushes')
plt.xlabel('# of pushes')
plt.ylabel('# of posts')
plt.xticks([10 * i for i in range(4)])
plt.show()
另外,也可以考慮直接畫出資料的散佈圖 (scatter plot),觀察相關性
plt.scatter(images, pushes)
plt.title('# of image v.s. push')
plt.xlabel('# of image')
plt.ylabel('# of push')
plt.axis('equal')
plt.show()
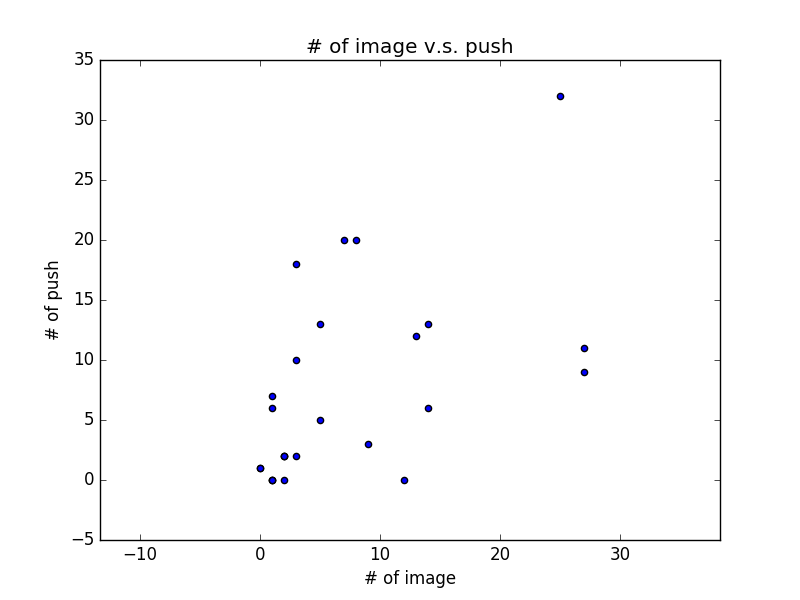
從 scatter plot 我們可以稍微看出圖片數與推文數的正相關性
結語:資料科學的三個面向
從這系列的文章,相信你已經看出所謂的資料科學與資料分析,其實可概分為三個面向:
- 資料處理,寫程式,架系統,對應資料的來源、儲存、處理、查詢等,
- 統計分析,數學,各種機器學習模型與技巧
- Domain knowledge,也就是到底要對著資料問什麼問題
所以如果你對資料科學有興趣,你可能是對架構系統有興趣(提供乾淨資料),或對於玩資料有興趣(喜歡統計分析,精通機器學習,或是有足夠的領域知識發掘好問題),也可以思考以你的背景從哪一塊切入會比較適合。
給初學者的 Python 網頁爬蟲與資料分析 (4) 擷取資料及下載圖片
本系列完整範例爬蟲程式
這篇文章會說明如何將各文章內的圖片下載到本機端,並計算、儲存圖片數。經過之前的步驟,我們已經有了文章列表,其格式是:
articles = [
{'push_count': 8, 'title': '[正妹] 韓國瑜的女兒', 'href': '/bbs/Beauty/M.1482411674.A.855.html'}
{'push_count': 5, 'title': '[正妹] 佐々木優佳里 Happiness', 'href': '/bbs/Beauty/M.1482414319.A.C09.html'}
{'push_count': 13, 'title': '[正妹] 甜美笑容 第一二五彈', 'href': '/bbs/Beauty/M.1482416491.A.656.html'}
...
]
因此,我們的步驟是:
- 連線到網站,取得該文章網頁 (
get_web_page()) - 找到文章內的圖片網址們 (
parse()) - 在本機新增以文章標題為名的資料夾,將圖片存到本機 (
save()) - 紀錄圖片數量;繼續巡訪下一篇文章直到沒有文章為止
程式碼如下,非常簡單:
PTT_URL = 'https://www.ptt.cc'
for article in articles:
page = get_web_page(PTT_URL + article['href'])
if page:
img_urls = parse(page)
save(img_urls, article['title'])
article['num_image'] = len(img_urls)
以下分別說明各步驟。
取得文章網頁
這部分之前已經說明過,只是文章的網址換一下而已。要注意的是 PTT 網頁內文章的 href 屬性是相對路徑,因此連線時要加上完整網址名稱 (PTT_URL)
找到文章內的圖片網址們
這部分一樣是用 BeautifulSoup 的 find_all() 來完成。我們先假設圖片網址一定是 “http://i.imgur.com” 開頭,用 Chrome 開發者工具檢視網頁區塊後,我們知道我們要找的是 <div id=”main-content”> 區塊內所有的 <a> 標籤,且 href 屬性是 “http://i.imgur.com” 開頭的連結:
def parse(dom):
soup = BeautifulSoup(dom, 'html.parser')
links = soup.find(id='main-content').find_all('a')
img_urls = []
for link in links:
if link['href'].startswith('http://i.imgur.com'):
img_urls.append(link['href'])
return img_urls
看到這邊你一定有疑問:imgur 網站圖片的網址不一定是 http 開頭,也可能是 https 開頭;網址也可能是 m.imgur.com 或 imgur.com,例如以下網址都是同一張圖片的合法網址:
test_urls = [
'http://i.imgur.com/A2wmlqW.jpg',
'http://i.imgur.com/A2wmlqW', # 沒有 .jpg
'https://i.imgur.com/A2wmlqW.jpg',
'http://imgur.com/A2wmlqW.jpg',
'https://imgur.com/A2wmlqW.jpg',
'https://imgur.com/A2wmlqW',
'http://m.imgur.com/A2wmlqW.jpg',
'https://m.imgur.com/A2wmlqW.jpg'
]
但我們的程式只能辨認出前兩種網址。當然你可以增加字串值與條件判斷去辨認更多種格式的網址,但較簡潔的方法是透過正規表示式 (Regular Expression) 指定字串的格式。例如能辨識出以上全部格式的正規表示式為:
'^https?://(i.)?(m.)?imgur.com'
”^” 表示字串開頭,字元緊接著 “?” 表示該字元可出現 0 或 1 次,所以 “^https?” 表示的是 “http” (s 出現 0 次) 或 “https” (s 出現 1 次) 開頭的字串,同理 (i.)? 表示 “i.” 可以出現 0 或 1 次。我們用 re.match() 判斷字串是否符合所定義的正規表示式:
import re
for url in test_urls:
print(re.match('^https?://(i.)?(m.)?imgur.com', url)) # 符合則回傳 SRE_Match Object, 不符合則回傳 None
# <_sre.SRE_Match object; span=(0, 18), match='http://i.imgur.com'>
# <_sre.SRE_Match object; span=(0, 18), match='http://i.imgur.com'>
# <_sre.SRE_Match object; span=(0, 19), match='https://i.imgur.com'>
# <_sre.SRE_Match object; span=(0, 16), match='http://imgur.com'>
# <_sre.SRE_Match object; span=(0, 17), match='https://imgur.com'>
# <_sre.SRE_Match object; span=(0, 17), match='https://imgur.com'>
# <_sre.SRE_Match object; span=(0, 18), match='http://m.imgur.com'>
# <_sre.SRE_Match object; span=(0, 19), match='https://m.imgur.com'>
因此,我們將 parse() 改寫為:
def parse(dom):
soup = BeautifulSoup(dom, 'html.parser')
links = soup.find(id='main-content').find_all('a')
img_urls = []
for link in links:
if re.match(r'^https?://(i.)?(m.)?imgur.com', link['href']):
img_urls.append(link['href'])
return img_urls
將圖片存到本機端
有了圖片網址,我們會創造一個以文章標題為名的資料夾,並將圖片下載到該資料夾內。在此要注意的有 3 點:
- 我們擷取了 imgur.com 網址的各種形式,但下載圖片時用的網址必須是 i.imgur.com 開頭,因此要把 m.imgur.com 換成 i.imgur.com,或把 imgur.com 補成 i.imgur.com
- 網址結尾不一定有 .jpg,為了順利下載,記得補上 .jpg。這些字串處理過程,就是資料淨化與清理的工作。
- 因為文章標題可能會有作業系統不支援的字元,所以
os.makedirs()可能會失敗,失敗時就無法創造資料夾,並印出 exception。要處理這個問題,一個解法是用正規表示式過濾系統不支援的字元,在此先略過。
def save(img_urls, title):
if img_urls:
try:
dname = title.strip() # 用 strip() 去除字串前後的空白
os.makedirs(dname)
for img_url in img_urls:
if img_url.split('//')[1].startswith('m.'):
img_url = img_url.replace('//m.', '//i.')
if not img_url.split('//')[1].startswith('i.'):
img_url = img_url.split('//')[0] + '//i.' + img_url.split('//')[1]
if not img_url.endswith('.jpg'):
img_url += '.jpg'
fname = img_url.split('/')[-1]
urllib.request.urlretrieve(img_url, os.path.join(dname, fname))
except Exception as e:
print(e)
到這邊為止,你的程式已經可以下載 PTT Beauty 板今日文章的圖片,並且有了今天每一篇文章的標題、推文數、圖片數、文章連結等資訊,你可以把資訊存成 json 檔案如下:
import json
with open('data.json', 'w', encoding='utf-8') as f:
json.dump(articles, f, indent=2, sort_keys=True, ensure_ascii=False)
這個簡單的範例還有許多可改進的地方,例如:處理文章標題的特殊字元,只有推文數多的文章才下載圖片、略過推文的圖片、支援更多圖床網址、多執行緒下載圖片等,但已經展示了一些基礎爬蟲技巧與概念。下一篇文章會說明如何做簡單的資料分析 (統計資料與畫圖)。
給初學者的 Python 網頁爬蟲與資料分析 (3) 解構並擷取網頁資料
本節 beautifulsoup 範例程式, Beauty 板爬蟲範例程式
網頁 = 由標籤 (tag) 所組成的階層式文件
你在瀏覽器看到的美觀網頁,主要由三個部分構成: HTML (網頁的骨架結構)、CSS (網頁的樣式) 與 JavaScript (在瀏覽器端執行,負責與使用者互動的程式功能)。對於網頁或爬蟲的初學者來說,最重要的觀念是了解:網頁就是由各式標籤 (tag) 所組成的階層式文件,要取得所需的網頁區塊資料,只要用 tag 與相關屬性去定位資料所在位置即可。例如以下是一個簡單的網頁及其原始碼:
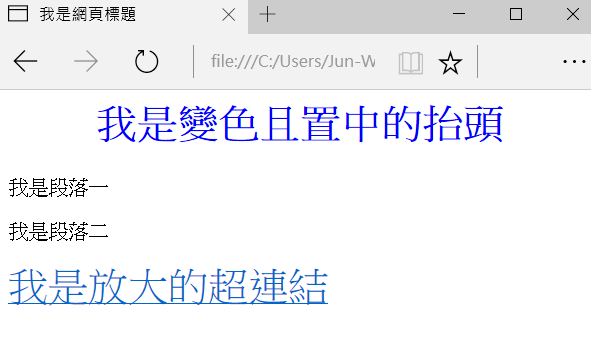
<html>
<head>
<title>我是網頁標題</title>
<style>
.large {
color:blue;
text-align: center;
}
</style>
</head>
<body>
<h1 class="large">我是變色且置中的抬頭</h1>
<p id="p1">我是段落一</p>
<p id="p2" style="">我是段落二</p>
<div><a href='http://blog.castman.net' style="font-size:200%;">我是放大的超連結</a></div>
</body>
</html>
HTML 文件內不同的標籤 (例如 <title>, <h1>, <p>, <a> 有著不同的語義,表示建構網頁用的不同元件,且標籤可以有各種屬性 (例如 id, class, style 等通用屬性, 或 href 等專屬屬性),因此我們可以用標籤 + 屬性去定位資料所在的區塊並取得資料。關於網頁架構還有另外一件事,就是它是階層式文件,例如以上的網頁架構可以如下表示:
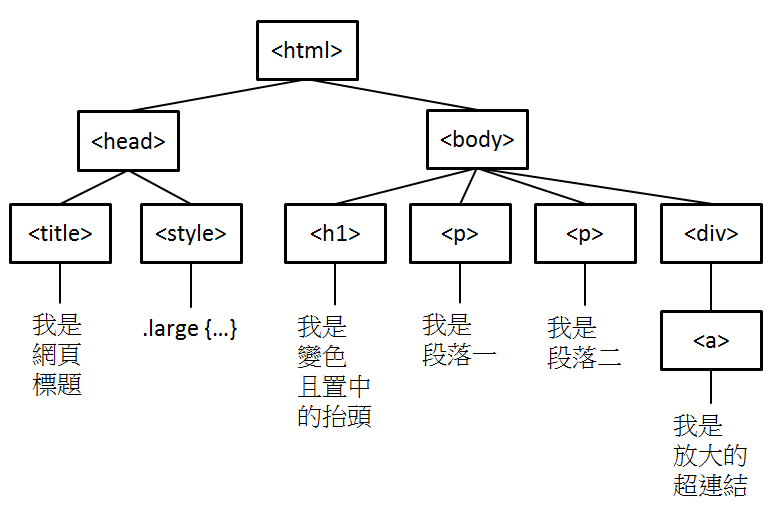
雖然在我們的範例中不會用階層結構去定位資料區塊,但知道這件事有助於你閱讀及理解網頁文件。
BeautifulSoup 入門
BeautifulSoup 是好學易用,用來解構並擷取網頁資訊的 Python 函式庫。給定以上的網頁文件,
html_doc = """
<html>
<head>
<title>我是網頁標題</title>
<style>
.large {
color:blue;
text-align: center;
}
</style>
</head>
<body>
<h1 class="large">我是變色且置中的抬頭</h1>
<p id="p1">我是段落一</p>
<p id="p2" style="">我是段落二</p>
<div><a href='http://blog.castman.net' style="font-size:200%;">我是放大的超連結</a></div>
</body>
</html>
"""
先創建一個 BeautifulSoup 物件,將網頁讀入
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup)
# <html>
# <head>
# <title>我是網頁標題</title>
# <style>
# .large {
# color:blue;
# text-align: center;
# }
# </style>
# </head>
# <body>
# <h1 class="large" style="">我是變色且置中的抬頭</h1>
# <p id="p1">我是段落一</p>
# <p id="p2" style="">我是段落二</p>
# <div><a href="http://blog.castman.net" style="font-size:200%;">我是放大的超連結</a></div>
# </body>
# </html>
接著就可以用 find(), find_all() 搭配 tag 名稱及屬性去定位資料區塊
soup.find('p') # 回傳第一個被 <p> </p> 所包圍的區塊
# <p id="p1">我是段落一</p>
soup.find('p', id='p2') # 回傳第一個被 <p> </p> 所包圍的區塊且 id="p2"
# <p id="p2" style="">我是段落二</p>
soup.find(id='p2') # 回傳第一個 id="p2" 的區塊
# <p id="p2" style="">我是段落二</p>
soup.find_all('p') # 回傳所有被 <p> </p> 所包圍的區塊
# [<p id="p1">我是段落一</p>, <p id="p2" style="">我是段落二</p>]
soup.find('h1', 'large') # 找尋第一個 <h1> 區塊且 class="large"
# <h1 class="large" style="">我是變色且置中的抬頭</h1>
find() 只回傳第一個找到的區塊,而 find_all() 會回傳一個 list, 包含所有符合條件的區塊。傳入的引數第一個通常是 tag 名稱,第二個引數若未指明屬性就代表 class 名稱,也可以直接使用 id 等屬性去定位區塊。定位到區塊後,可以取出其屬性與包含的字串值
paragraphs = soup.find_all('p')
for p in paragraphs:
print(p['id'], p.text)
# p1 我是段落一
# p2 我是段落二
a = soup.find('a')
print(a['href'], a['style'], a.text)
# http://blog.castman.net font-size:200%; 我是放大的超連結
print(soup.find('h1')['class']) # 因為 class 可以有多個值,故回傳 list
# ['large']
如果你要取得的屬性不存在,直接使用屬性名稱會出現錯誤訊息,因此若你不確定屬性是否存在,可以改用 get() 方法
print(soup.find(id='p1')['style']) # 會出現錯誤訊息, 因為 <p id="p1"> 沒有 style 屬性
print(soup.find(id='p1').get('style')) # None
其他詳細用法可參考 BeautifulSoup 的官方文件
使用 Chrome 的開發者工具找到資料區塊的 tag 及屬性
假設你有一個想爬的網頁,要怎麼知道資料區塊所在的標籤及屬性呢?在此我們使用 Chrome 的開發者工具,以 Ptt Web 版 Beauty 板首頁為例,用 Chrome 連上 https://www.ptt.cc/bbs/Beauty/index.html , 接著按下 F12 或從選單啟動開發者工具
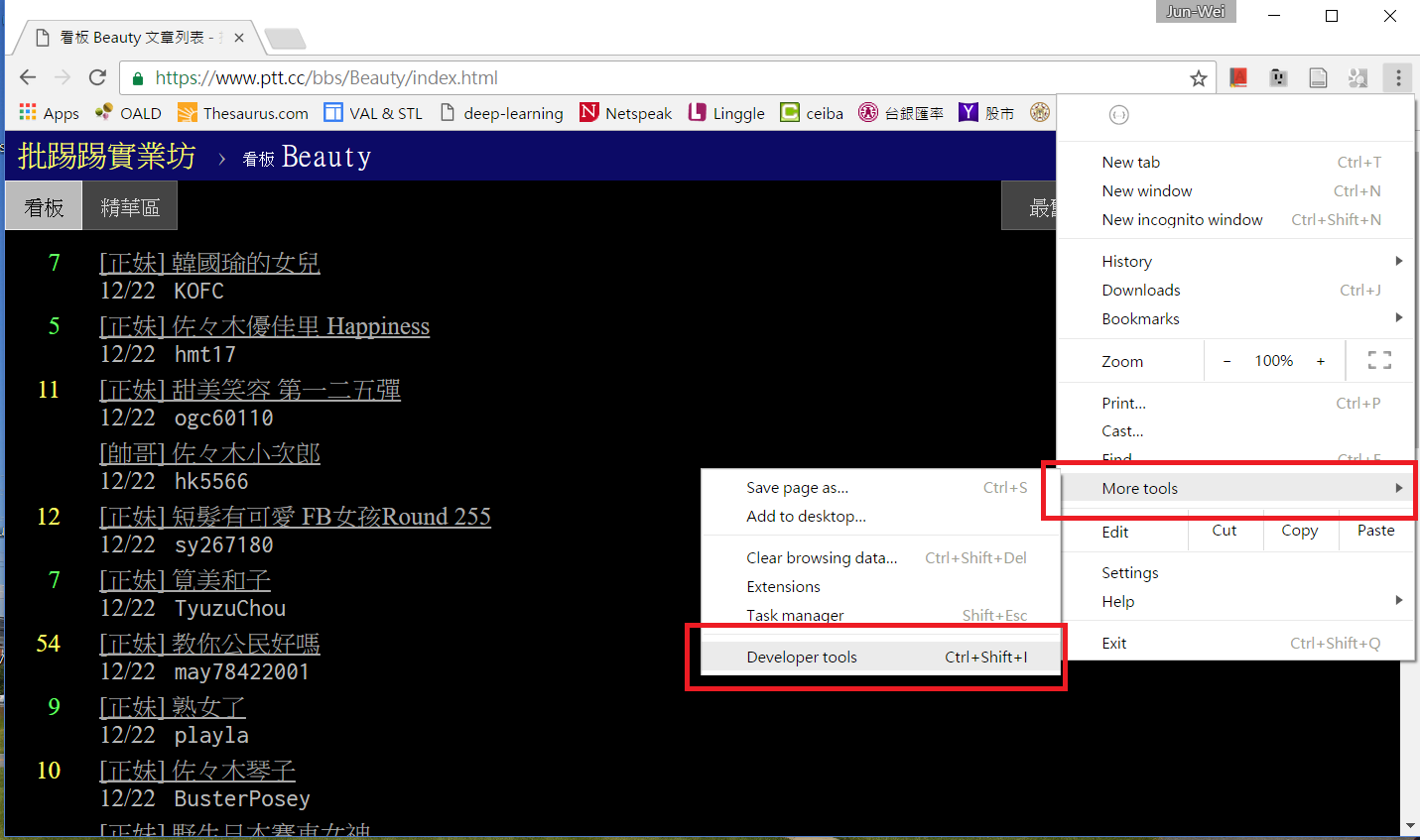
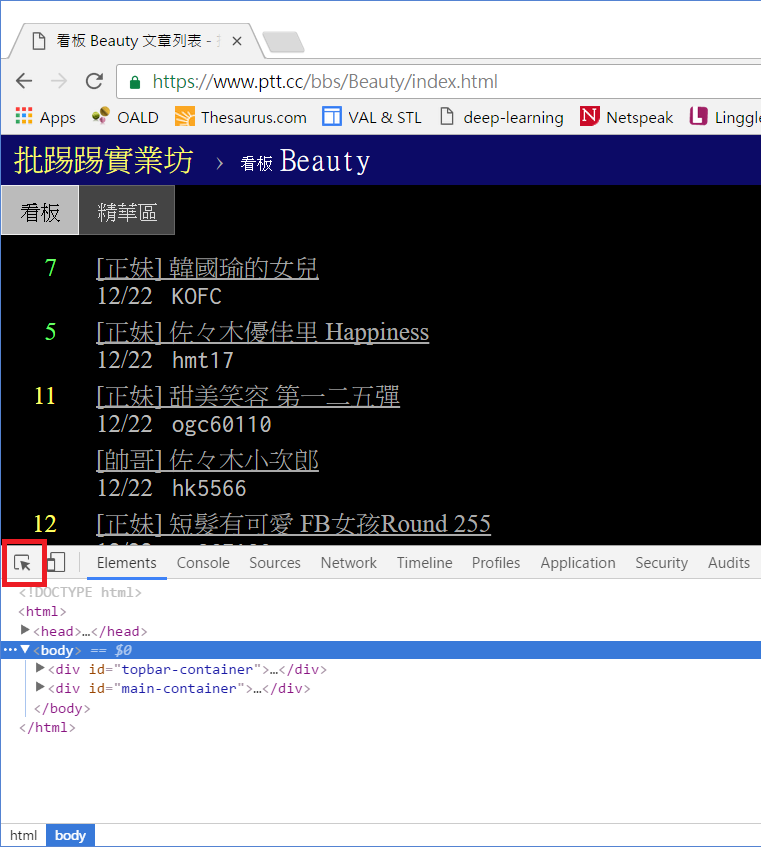
下方會跑出開發者工具的操作區,點選左上角的箭頭按鈕後,再點擊網頁上你想要定位的資料區塊,該區塊的 HTML 碼就會顯示在下方。當然你也可以直接檢視網頁原始碼或檢視上一篇教學中用 get_web_page() 所取得的網頁文件,但善用開發者工具可以加速你的搜尋。
PTT Beauty 板範例實戰
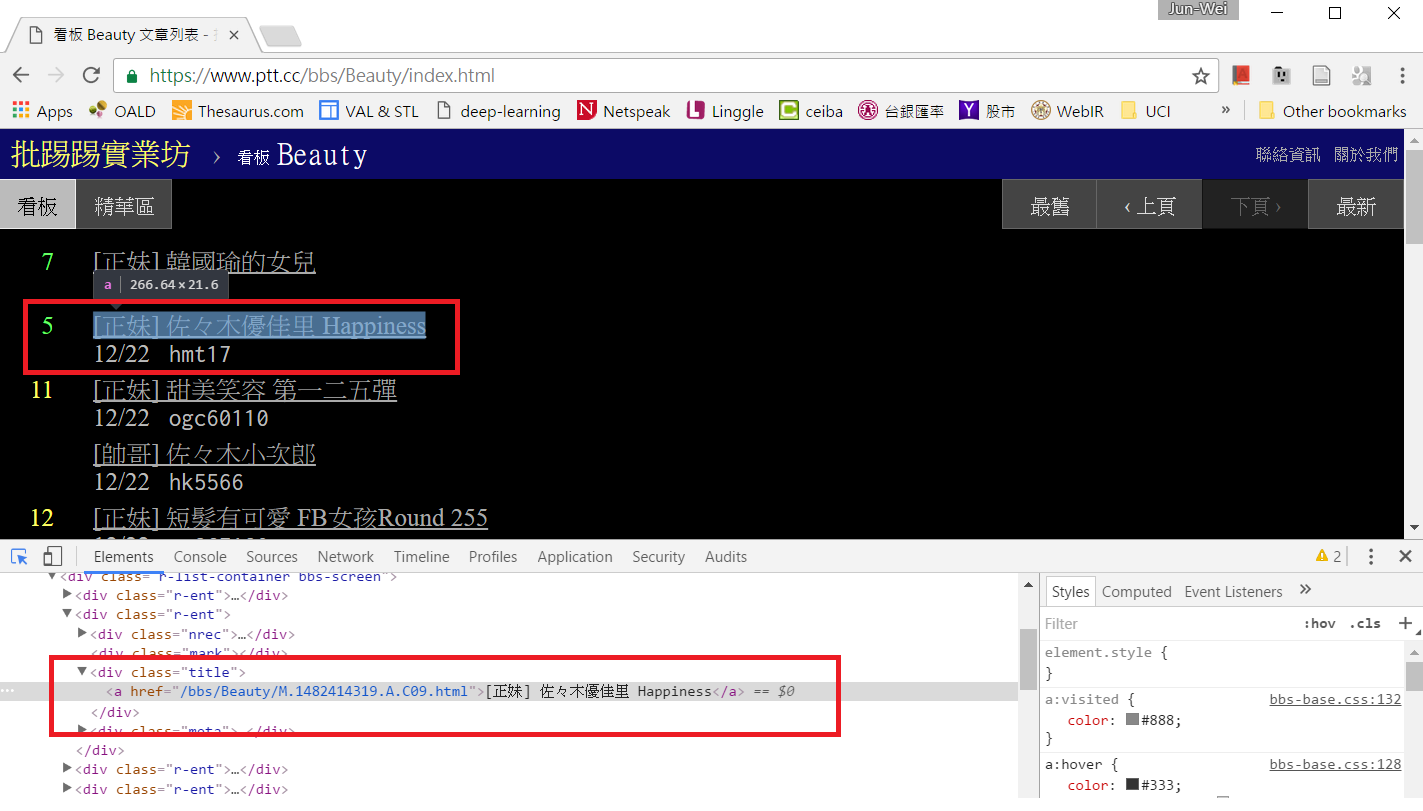
檢視網頁原始碼後我們知道,網頁上的每一篇貼文都是由 <div class=”r-ent”> 的區塊包圍起來,裡面分別由 <div class=”nrec”> 區塊顯示推文數,<div class=”title”> 區塊及 <a> 區塊顯示文章連結及文章標題,<div class=”date”> 區塊顯示發文日期
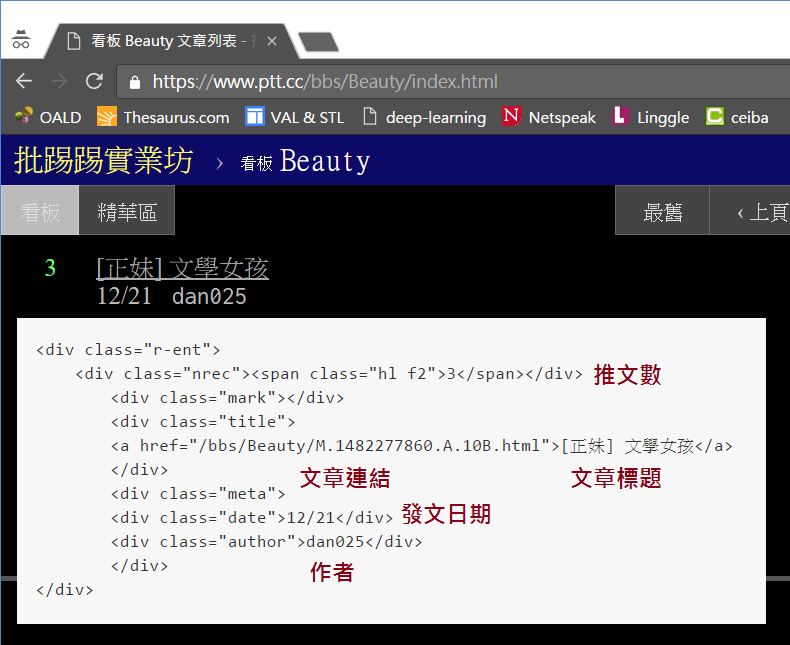
因此,若已經取得網頁文件,我們可以用 find_all() 找出所有<div class=”r-ent”> 區塊,並逐一巡訪,取得資料:
def get_articles(dom, date):
soup = BeautifulSoup(dom, 'html.parser')
articles = [] # 儲存取得的文章資料
divs = soup.find_all('div', 'r-ent')
for d in divs:
if d.find('div', 'date').string == date: # 發文日期正確
# 取得推文數
push_count = 0
if d.find('div', 'nrec').string:
try:
push_count = int(d.find('div', 'nrec').string) # 轉換字串為數字
except ValueError: # 若轉換失敗,不做任何事,push_count 保持為 0
pass
# 取得文章連結及標題
if d.find('a'): # 有超連結,表示文章存在,未被刪除
href = d.find('a')['href']
title = d.find('a').string
articles.append({
'title': title,
'href': href,
'push_count': push_count
})
return articles
使用 get_articles() 及上一篇教學的 get_web_page(),取得今日文章資訊
page = get_web_page('https://www.ptt.cc/bbs/Beauty/index.html')
if page:
date = time.strftime("%m/%d").lstrip('0') # 今天日期, 去掉開頭的 '0' 以符合 PTT 網站格式
current_articles = get_articles(page, date)
for post in current_articles:
print(post)
# {'push_count': 8, 'title': '[正妹] 韓國瑜的女兒', 'href': '/bbs/Beauty/M.1482411674.A.855.html'}
# {'push_count': 5, 'title': '[正妹] 佐々木優佳里 Happiness', 'href': '/bbs/Beauty/M.1482414319.A.C09.html'}
# {'push_count': 13, 'title': '[正妹] 甜美笑容 第一二五彈', 'href': '/bbs/Beauty/M.1482416491.A.656.html'}
# {'push_count': 0, 'title': '[帥哥] 佐々木小次郎', 'href': '/bbs/Beauty/M.1482417495.A.733.html'}
# {'push_count': 14, 'title': '[正妹] 短髮有可愛 FB女孩Round 255', 'href': '/bbs/Beauty/M.1482419748.A.D25.html'}
# {'push_count': 7, 'title': '[正妹] 筧美和子', 'href': '/bbs/Beauty/M.1482419973.A.32C.html'}
# {'push_count': 58, 'title': '[正妹] 教你公民好嗎', 'href': '/bbs/Beauty/M.1482420690.A.AE7.html'}
# {'push_count': 9, 'title': '[正妹] 熟女了', 'href': '/bbs/Beauty/M.1482420814.A.021.html'}
# {'push_count': 10, 'title': '[正妹] 佐々木琴子', 'href': '/bbs/Beauty/M.1482421163.A.C42.html'}
# {'push_count': 0, 'title': '[正妹] 野生日本賽車女神', 'href': '/bbs/Beauty/M.1482421895.A.F6B.html'}
這樣就取得今天全部的 Beauty 板文章了嗎?聰明的你一定想到了:如果不只首頁,前一頁還有今天的文章怎麼辦?這就留給各位自行練習了 (提示:找到前一頁的連結,連線並取得該頁資料後,一樣用 get_articles 爬取文章資料),我們會在教學結束後的範例提供完整程式碼。下一篇文章會說明如何連結到 current_articles 內的文章,抓圖並計算每一篇文章的貼圖數。
給初學者的 Python 網頁爬蟲與資料分析 (2) 套件安裝與啟動網頁爬蟲
範例: PTT Beauty 板今日圖片下載器
PTT Beauty 板今日圖片下載器,會把表特板今天所有文章的圖片下載到本機端,同時儲存一些文章資訊。本系列文章藉由會實作這個範例,說明 Python 網頁爬蟲與資料分析的入門技巧。
套件安裝
首先請確定你的電腦已經安裝 Python 3 以及 pip (本文使用的環境是 Python 3.5.2 與 pip 9.0.1)
> python --version
Python 3.5.2
> pip --version
pip 9.0.1 from c:\virtualenv\ptt-beauty-py35-64\lib\site-packages (python 3.5)
接著安裝所需套件,你可以依照 requirement.txt 中所列的套件一一安裝,也可以一次全部安裝
pip install -r requirement.txt
接著在命令列輸入以下指令,若沒有任何訊息出現則代表套件安裝成功
python -c "import requests; import bs4; import matplotlib"
與網站 Server 溝通並取得網頁資料
PTT Web 版 Beauty 板首頁 https://www.ptt.cc/bbs/Beauty/index.html 在瀏覽器看起來是這樣的
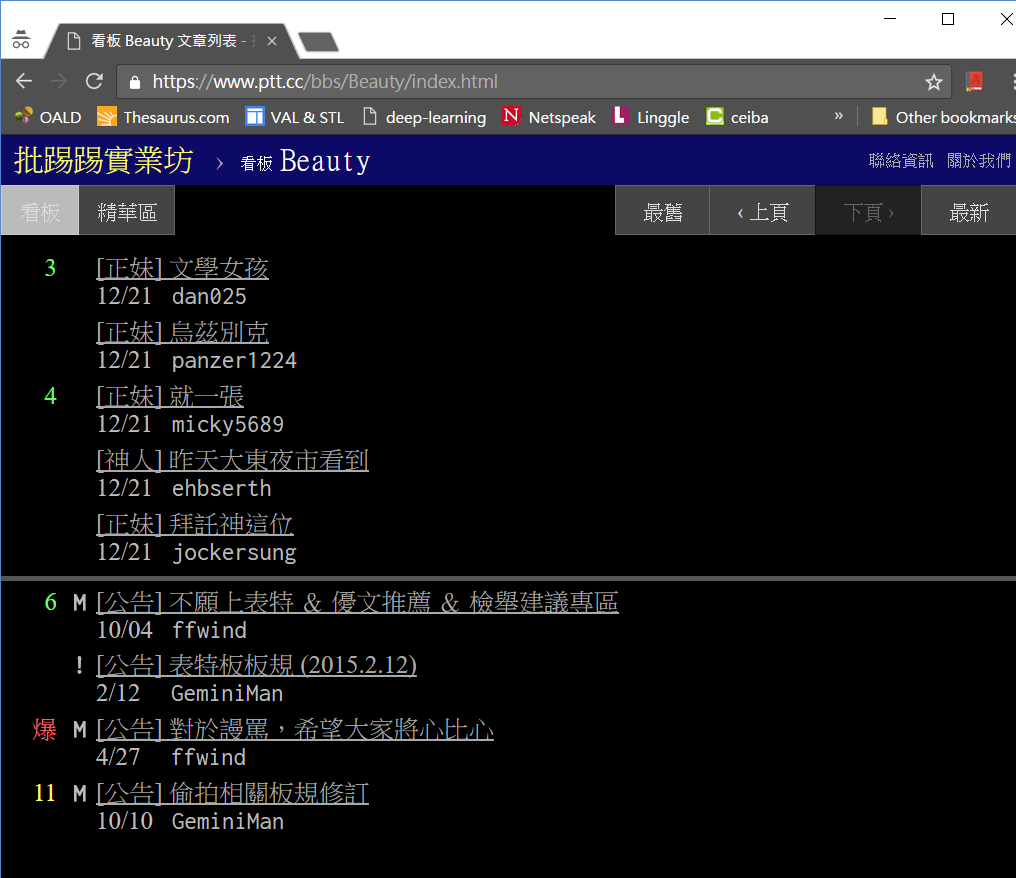
要透過 Python 取得該頁資料,我們使用 requests 套件的 requests.get() 方法, 首先定義 get_web_page() 函式
def get_web_page(url):
resp = requests.get(
url=url,
cookies={'over18': '1'}
)
if resp.status_code != 200:
print('Invalid url:', resp.url)
return None
else:
return resp.text
requests.get() 需要提供網址作為引數, 而 cookies={'over18': '1'} 是 PTT 網站有些板會詢問你是否已滿 18 歲, 因此將回答先存在 cookie 中一併傳給 server. requests.get() 的結果是 request.Response 物件, 我們可以先透過該物件的 statu_code 屬性取得 server 回覆的狀態碼 (例如 200 表示正常, 404 表示找不到網頁等), 若狀態碼為 200, 代表正常回應, 再透過 text屬性取得 server 回覆的網頁內容. 若狀態碼異常則回覆 None.
定義好 get_web_page() 函式之後, 就能呼叫它來取得網頁內容:
page = get_web_page('https://www.ptt.cc/bbs/Beauty/index.html')
if page:
print(page)
結果為
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>看板 Beauty 文章列表 - 批踢踢實業坊</title>
(...略)
</head>
<body>
<div id="topbar-container">
<div id="topbar" class="bbs-content">
<a id="logo" href="/">批踢踢實業坊</a>
<span>›</span>
<a class="board" href="/bbs/Beauty/index.html"><span class="board-label">看板 </span>Beauty</a>
<a class="right small" href="/about.html">關於我們</a>
<a class="right small" href="/contact.html">聯絡資訊</a>
</div>
</div>
(...略)
<div class="r-ent">
<div class="nrec"><span class="hl f2">3</span></div>
<div class="mark"></div>
<div class="title">
<a href="/bbs/Beauty/M.1482277860.A.10B.html">[正妹] 文學女孩</a>
</div>
<div class="meta">
<div class="date">12/21</div>
<div class="author">dan025</div>
</div>
</div>
<div class="r-ent">
<div class="nrec"></div>
<div class="mark"></div>
<div class="title">
<a href="/bbs/Beauty/M.1482285364.A.D29.html">[正妹] 烏茲別克</a>
</div>
<div class="meta">
<div class="date">12/21</div>
<div class="author">panzer1224</div>
</div>
</div>
(...略)
回傳的內容的確是瀏覽器所看到的內容,而且以第一篇貼文為例,我們可以看到它包含了推文數、文章連結、文章標題、貼文日期等我們所需要的資訊。下一篇文章會說明如何使用 BeautifulSoup 套件解構網頁內容,將資料取出。
