給初學者的 Python 網頁爬蟲與資料分析 (1) 前言
前言
這系列文章是與 Pycone 松果城市合作,給初學者的網頁爬蟲與資料分析教學,如果你對於 Python 有粗淺認識 (知道 Python 的資料型態, 控制結構, 寫過一些小程式), 想進一步知道要怎麼使用 Python 擷取網頁資訊並簡單做些資料分析 (如圖表、統計資料、相關性等),這系列文章可以帶你入門。一般想要寫網頁爬蟲的人,不會只想要擷取資料,他們真正想要的通常是資料分析,找出資料能提供的資訊,或使用資料驗證自己的假設,Python 也有許多資料處理與展示的好用套件可以使用 (如 NumPy, scikit-learn, pandas),這系列文章會先略過這些套件,教你直接用程式計算統計資料與畫圖,以便讓你更了解套件底層的邏輯,之後學習這些套件時會更容易上手。
步驟拆解
網頁爬蟲與資料分析可以分成以下步驟:
- 資料來源: 資料來源可以是別人整理好的資料(如政府 open data, 整理好的 csv 或 json 等文字檔), 也可以是自行從公開網頁擷取的資料 (本文會使用 PTT 網站作為範例)
- 啟動爬蟲: 如果資料不是整理好的,而是必須從公開網頁爬取,就必須利用程式與網站 server 連線取得網頁資訊 (本文會示範用 request 套件與 PTT 網站溝通)
- 資料擷取與資料淨化: 從公開網頁爬取的整個頁面,通常只有一部分是你需要的,因此要利用程式解構網頁架構,取得所需資料 (本文使用 BeautifulSoup 套件解構網頁文件,擷取所需資料); 另外,在擷取過程中或擷取後,資料通常會有些雜訊 (例如錯誤的時間格式, 英文數字混雜等),此時也要利用程式做資料淨化以便後續分析 (本文會示範利用簡單的正規表示式 regular expression 做資料過濾與淨化)
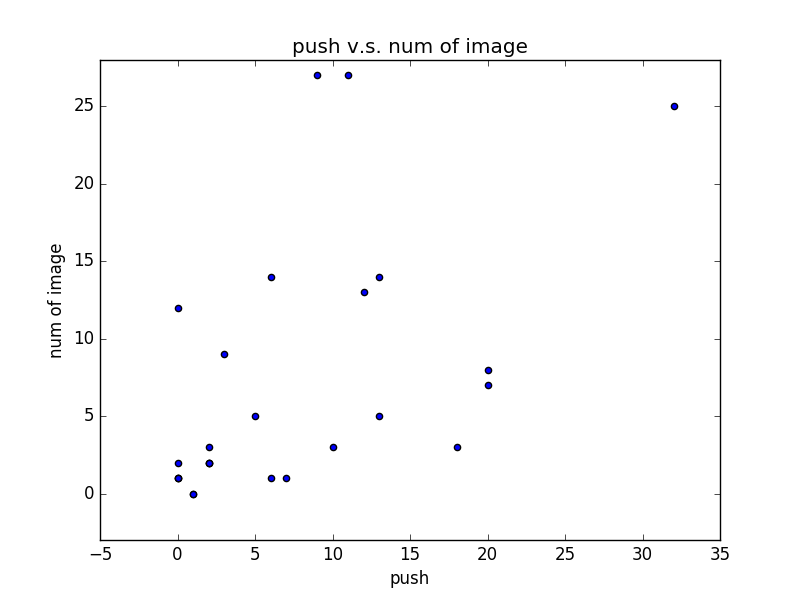
- 資料分析: 爬蟲把 raw data 爬下來之後, 你可能會想要分析資料,例如跑些統計資訊或檢查資料維度間的相關性,驗證你的假設 (本文會示範計算文章內圖片數量與推文數的相關係數)
- 資料展示: 用圖表、網頁等展示資料 (本文會示範將 PTT Beauty 版文章內的圖片存到本機端,並畫出文章內圖片數量與推文數的分佈圖)
範例程式: PTT Beauty 板今日圖片下載器
本文會教你實作一個簡單的圖片下載器,它會連上 PTT Web 版的表特板首頁,然後把今天所有文章內含的圖片下載到本機端,同時儲存各文章的標題、推文數、內含圖片數,以便後續資料分析。我們會計算圖片數與推文數的相關係數(是否張貼越多圖片的文章會得到越多推?),並畫出資料分布圖。在過程中你會學到如何用 Python 連線到網站,如何解構網頁文件並擷取、儲存資料,以及資料分析與展示的基本技巧。範例成果如下:
> python analyzer.py
推文數: [18, 20, 0, 0, 3, 6, 2, 12, 1, 13, 11, 5, 0, 20, 1, 7, 6, 2, 2, 0, 0, 32, 10, 13, 9, 2]
圖片數: [3, 7, 1, 12, 9, 1, 2, 13, 0, 5, 27, 5, 1, 8, 0, 1, 14, 2, 3, 2, 1, 25, 3, 14, 27, 2]
相關係數: 0.5259
First Quarter at UCI - Question behind the Question
來了之後我覺得收穫最大的,就是資格考的準備課程,一般 CS 學生大概不覺得考試有什麼困難,我在台大更是第一個學期就考完了資格考 (離散/線代/OS/Archi/Algo/DS)。但是因為我念的 Software Engineering program 隸屬 Informatics department 底下,這整個 department 都怪怪的…嗯我是說這是一個跨領域的學門,即使是軟體工程,也特別偏重 human factor, human computer interaction, social impact 等與社會科學較相關的因素,所以我們的資格考不考 CS 專業科目,相反的,你必須用六個小時回答四道情境或申論題,然後在答案裡展現出你在整個軟體工程領域的學術與實務知識,考試結果有 PhD Pass, Master Pass 與 Fail 三種,教授們對於 PhD Pass 的答案更是有高度的期待,你必須呈現出你的抽象思考與解題框架,只引用參考文獻裡面的知識是不夠的。這是什麼意思呢?假設你要回答以下問題:
你負責規劃開發一個醫療資訊系統,而在軟體開發實務中有所謂的 A 流程/技術與 B 流程/技術,你覺得以這個系統來說,採用 A 或 B 那個比較好?為什麼?
身為一個工程師,我們解決問題的流程通常如下:
- 大概了解要解決什麼問題,需要什麼核心功能
- 直接 google 網路上最常見的解法,找最多人使用/文件最齊全的技術或工具
- 直接把找到的解法套下去用,看看效果如何
- 問題不一定要完全解決,只要使用者/利害關係人沒意見,就可以結案。然後接著處理下一個問題,因為現實世界中要解決的問題不只這一個。
好了,套用工程師思維,我很可能會先描述一下我對這個系統的假設,再依我對 A/B 流程或技術的實務經驗或相關論文的理解,選擇其中一個,並說明選擇的理由,為什麼我的選擇比較好,大概幾百字或頂多一頁 A4 就可以答完了。
這個理所當然的回答,大概只能得個 Master Pass.
真正有病的…嗯我是說真正完整的回答,不能只回答問題本身,你要回答的,是問題背後的問題。比如說:
什麼叫做”好”?在你假設的系統需求下,好的定義是什麼?它有可能改變嗎? A/B 流程或技術的步驟或核心是什麼?是它們的哪一個環節比較符合你對於好的定義?就算你選擇了其中一個,另外一個在什麼情況下會比較好?甚至,要符合你所定義的好,採用哪個流程/技術根本不是重點,重點在其他地方?
看出來了嗎?你必須小題大作,題目要你選邊站,但你不能真的只選一邊,你必須要兼顧到兩邊,甚至有可能選哪一邊根本不是重點。所以首先你要把題目不清楚的地方都做好假設,接著拆解問題中專有名詞的概念,架構你答題的框架,最後把問題放入你的框架中回答,過程中參考文獻不是拿來答題用的,你必須先有自己的論點,然後引用文獻支持你的論點。這沒有個兩千字是寫不完的。
如果是在公司或與人口頭溝通時搬出這套,大概就直接被轟出門了,工程師思維的我內心的 OS 也是:誰有空聽你在那邊嘴這麼多?我甚至覺得雖然這跟寫論文所需的 critical thinking 有關,但很多時候論文只是起源於一個待解的問題,把解法想出來,related work, motivation 跟 evaluation 補一補就寫好了,要嘴到這樣也太走火入魔了吧!但是,我從一開始的不以為然,慢慢地也學著接受這個考驗,除了考試就是這麼現實以外,同時它也是一種思考訓練,最重要的是,它是訓練我運用文字跟嘴砲的好機會,因為從古希臘以降的西方哲學告訴我們,這個世界就是嘴出來的,你雖然不屑,但你會發現:你想嘴的時候還嘴不出來,因為你念的書不夠多。
這對我來說比考數學或專業科目難多了,根本是知識累積跟英文寫作的雙重難題,但我很樂意接受這個挑戰,畢竟這就是我來的目的。
First Quarter at UCI - The Difference
在 UCI 的第一個 quarter 結束了。身為一個在台灣也念過一陣子博士班的人,對於在國內外念書尤其是做研究的環境差異有些粗淺的經驗分享。
學習動機
首先是(國際)學生的學習動機。漂洋過海來的國際學生,在繁複的申請流程中就已經初步確認了動機,畢業後的目標也很明確,到校後就算沒有動機,為了畢業,課業上也不太會打混,這很明顯的反映在全班平均成績上。在大家都滿認真的情況下,自己相對地也會比較辛苦。另一方面,我最喜歡的是 lab meeting 時討論的氣氛,因為美國碩士可以不用寫論文,而大部分目標放在工作的碩士生,沒興趣也不需要做研究,換句話說,會來參與討論的都是對研究有興趣的人。這個制度一方面讓博士生有更大的 lab 空間 (碩士生沒有座位),一方面又可以減少參加 lab meeting 的人數,讓會議得以更有效率及建設性地進行。在台灣因為碩士也要寫論文,如果學生對研究沒興趣卻被逼著做研究,跟他們在研究上的互動簡直是對彼此的折磨 (報個 paper 報得亂七八糟,問個問題也一問三不知)。但是這是否代表台灣也該引進 course track 的碩士制度?不一定,因為台灣跟美國的環境不同,來美國念碩士的國際學生,很多人根本已經有數年工作經驗,或這是他們的第二碩士,換言之,他們已經有解決問題的能力,只是需要學位當作工作的敲門磚而已;而台灣碩士班的學生大多是大學直升,學習動機也有差,寫論文能學到的解決問題的能力也的確是修課(聽講、作業、考試)學不到的。
修課壓力
其次是修課,UCI 是 quarter 制,以一般 CS 相關課程來說,在 10 週之內會完成 3 次程式作業加期中期末考,所以通常一開學就會處在備戰狀態了,跟學期制前兩週還在收心閒晃決定要修什麼課的氣氛差很多,也因為節奏緊湊的關係,修個三門主課就大概會耗掉全部的課餘時間,因為你沒有太多時間慢慢準備作業跟考試。壓力是有的,但我個人反而比較喜歡這種節奏,可以早點把 coursework 處理完,然後專心在研究上。對於有工作經驗的人來說,修課不是什麼難題;對博士生來說,修課對研究也不一定有幫助,所以能早點結束比較好。對於只是需要學位求職的人來說,碩士通常 4 個 quarter (1年3個月) 就可以拿到,也比較理想。
討論課與大量閱讀
上面提到的”修課不是什麼難題”指的是類似我們在台灣上的傳統課程(聽講、作業、考試),但是這裡有另外一種課程是類似討論課,也就是讓你課前讀 paper 寫摘要評論,課堂上發言討論的,對我這種習慣傳統 CS 課程的學生來說就會痛苦很多,一方面是讀寫說的速度都不如 native speaker,一方面是不習慣上課發言。像我這個 quarter 剛好修到兩門都是這種的,一個禮拜要讀 6-8 篇 paper,課前要繳交摘要評論,上課太安靜也會被點名發言。尤其如果你的 program 或 department 有些跨到社會科學領域,像我所在的 Software Engineering program / Informatics department,就一堆這種課,有的甚至是混合,不只要讀 paper 寫評論,程式作業也沒少的。我只能說我的修課壓力大部分來自這種課,不過經過第一個 quarter 的洗禮之後,我體認到這種課才是我,或說一個博士生需要的,因為這剛好可以增加我的知識廣度、訓練我的思考跟表達。當然對於碩士生來說就不一定需要。
研究發表
以博士生最主要的工作跟畢業門檻:發 paper 來說,雖然我還沒有資格多嘴,但我可以肯定的是在台灣念絕對能發 top conference or journal paper,我在台大跟清大實驗室的同學跟學長們就是最好的實例,我自己之前在台大做的東西最近也上了不錯的 conference;找教職方面則不得而知,但台大電機與清大資工近年也聘了幾個土博助理教授。單純就發表來說在台灣念是沒有問題的。
經濟支持
最後還是要回到現實面,我覺得支持博士生自保生活無虞,應該是對於學校最基本的要求,這已經跟直接就業能賺到的錢比起來少很多了。我個人經驗是:在美國雖然拿的錢仍是低收入戶等級,一般博士生的 support package (e.g. 學費全免, 做 TA 或 RA 賺生活費) 至少能自保生活無虞;在台灣則很難說,跟你研究的領域是否熱門、老闆接計畫的能力、組織是否有錢 (例如中研院的博士學程) 高度相關,大好大壞都有,而我是偏壞的那邊。或許我也該感謝這個因素推了我一把。 (待續)
再探 Robot Framework 與 Test Case 撰寫的 Best Practice
因為工作的關係又碰到了 Robot Framework,之前用它寫 test case 時比較隨性,這一次因為要將其導入並介紹給團隊,花了些時間看了官方文件跟一些 best practices,也有些實作經驗可分享。
什麼是 Robot Framework, 它能做什麼
Robot Framework 簡單來說就是一個讓你撰寫 keyword driven script 的 framework. 根據你想做的事情引入不同的 library 之後,就能使用各種 keyword 去兜出你想完成的工作。所以理論上它能夠做到 Python 可以做到的任何事情,反正如果沒有現成的 library 或 keyword 就自己寫即可。例如我們寫 Python 時經常用 requests 與 server 溝通:
import requests
url = 'http://yourhost.com'
payload = {'uname': 'user', 'pwd': 'password'}
resp = requests.post(url, data=payload)
print resp.status_code # 200
如果改用 RobotFramework 來寫的話,就引入 RequestsLibrary 即可:
*** Settings ***
Library RequestsLibrary
*** Test Cases ***
Post request
Create Session my_session http://yourhost.com
&{params}= Create Dictionary uname=user pwd=password
${resp}= Post Request alias=my_session uri=/ data=&{params}
Log ${resp.status_code}
我們可以看到 Create Session 與 Post Request 等 keywords 就是在做 requests 的 requests.post(),而事實上 RequestsLibrary 也的確是 requests 的 wrapper, 把 requests 能做到的事情打包成 keywords 讓你在 Robot Framework 裡面使用。再看一個 webdriver 的例子,用 Python 驅動 browser 去點擊或輸入網頁是這樣寫:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://yourhost.com')
element = driver.find_element_by_id('THE_ID')
element.send_keys('VALUE')
element = driver.find_element_by_xpath('THE_XPATH')
element.click()
在 Robot Framework 中則是引入 Selenium2Library:
*** Settings ***
Library Selenium2Library
*** Test Cases ***
Open browser and run
Open Browser http://yourhost.com chrome
Wait Until Element Is Visible id=THE_ID
Input Text id=THE_ID VALUE
Wait Until Element Is Visible xpath=THE_XPATH
Click Element xpath=THE_XPATH
同樣地,Open Browser, Wait Until Element Is Visible, Click Element 等都是 Selenium2Library 提供的 Keywords。當然,你也可以用 Keywords 組成自己的 Keyword (Wait And Click, Wait And Input):
*** Settings ***
Library Selenium2Library
*** Test Cases ***
Open browser and run
Open Browser http://yourhost.com chrome
Wait And Input id=THE_ID VALUE
Wait And Click xpath=THE_XPATH
*** Keywords ***
Wait And Input
[Arguments] ${locator} ${text}
Wait Until Element Is Visible ${locator}
Input Text ${locator} ${text}
Wait And Click
[Arguments] ${locator}
Wait Until Element Is Visible ${locator}
Click Element ${locator}
如果沒有現成的 Keywords 可用,自己寫一個也很方便,例如這個做 Base64 編碼的 class:
import base64
class Base64Library:
def base64_encode(self, text):
return base64.b64encode(text)
只要路徑正確,就能在 test script 內引用自己定義的 keyword (Base64 Encode):
*** Settings ***
Library Base64Library.py
*** Test Cases ***
Self-defined Keywords
${encoded}= Base64 Encode abc123
Log ${encoded} # YWJjMTIz
當然常見的變數宣告、參數、If-else、迴圈等,也都可以使用。
為什麼要用 Robot Framework
雖然 Robot Framework 可以做到幾乎任何 Python 能做的事情,但看到這邊你一定有個疑問:為何我還要為了這個 framework 去查各種 library 與 keyword 的用法,直接寫 Python code 不是快得多嗎?沒錯,如果只是要翻譯 Python code,根本不必用到這個 framework,這個 framework 是用在自動化測試,尤其是自動化驗收測試 (acceptance testing) 上的。使用 Robot Framework 做自動化測試的好處有:
-
Keyword Abstration. 從前面的例子可以看到,雖然我們能夠直接寫 Python code, 但是 Robot Framework 有可能已經幫我們把好幾行程式碼濃縮成一個 keyword,例如使用 webdriver 時我們常常在等某個 DOM element 出現,在 python 裡面可能要寫個 try block 之類的去處理,但用 Robot Framework + Selenium2Library 一個關鍵字就搞定了 (
Wait Until Page Contains / Wait Until Element Is Visible等);另外 keyword driven script 對於程式經驗較少的人來說也會比 Python 或 Java 程式碼容易上手;最後,自訂關鍵字的架構更可以把操作步驟一路抽象到自然語言層級,達到 “Test case 即註解” / “Test case 即文件” 的地步。這部分後面會再說明。 -
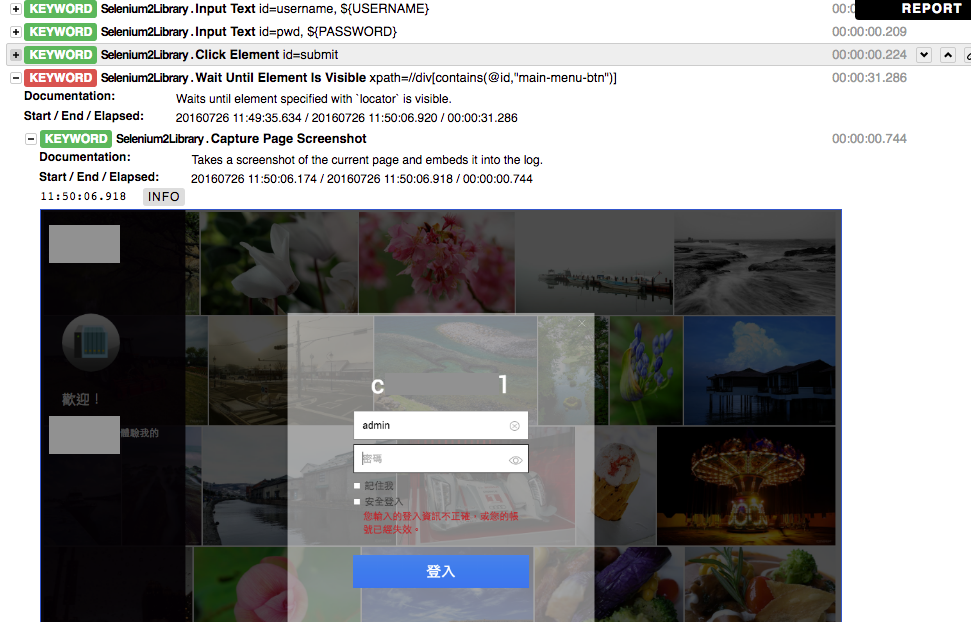
Test Report and Jenkins Integration. 它的報表與 Jenkins 整合功能大概是很多人選擇它的原因。Test script 執行之後會自動產生 HTML log,若 test case fail 會顯示停在哪一步,若是可以抓圖的話也會幫你把畫面抓下來,如下圖。當然它也支援一些測試相關功能,如 tag, test setup/teardown 等,Jenkins 也有 plugin 能顯示報表內容。
- Human Readable Acceptance Test. 把 test case 的步驟用自然語言描述,讓不寫程式的人 (工讀生/PM/老闆) 都能看懂,是 Robot Framework 官方文件的建議寫法,但很多人往往只著重在把程式邏輯翻譯成 test script,這樣固然可以享受到 Robot Framework 的測試報表及 CI 整合等好處,但沒有利用到它全部的優點,比較可惜。以下分享一些 best practices.
Robotframework 的 Do’s and Dont’s: 怎麼寫易維護的 Test Case
剛開始寫 Robot Framework test script 的人,往往著重在把測試程式的邏輯翻譯成 keyword 的形式,這個起手式沒錯,例如上面的 webdriver 例子,直接等待並操作 DOM elements:
*** Settings ***
Library Selenium2Library
*** Test Cases ***
Open browser and run
Open Browser http://yourhost.com chrome
Wait Until Element Is Visible id=THE_ID
Input Text id=THE_ID VALUE
Wait Until Element Is Visible xpath=THE_XPATH
Click Element xpath=THE_XPATH
...
用了一段時間之後,你可能會將測資設為變數,增加使用彈性,也可能把常用的實作細節包裝成自訂 keyword, 例如:
*** Settings ***
Library Selenium2Library
*** Variables ***
${HOST} http://yourhost.com
${BROWSER} chrome
${TEST_VALUE}
*** Test Cases ***
Open browser and run
Open Browser ${HOST} ${BROWSER}
Wait And Input id=THE_ID {TEST_VALUE}
Wait And Click xpath=THE_XPATH
...
*** Keywords ***
Wait And Input
...
Wait And Click
...
做到這一步其實已經有一定的彈性,但還是有一些缺點,最明顯的就是只看得出 test case 怎麼做 (How),但看不出它在做什麼 (What)。你要測試的 test requirement (system responsibility),與實作細節 (按鈕的 Xpath 或 id) 顯然無關。另外,如果其他 test script 也要用相同的自定義 keywords 怎麼辦?或日後 test case 一多,該如何降低維護成本?要比較好地處理這些問題,我們要回到驗收測試的基本精神:驗收系統功能,在不知道系統的介面及實作細節的前提下,利害關係人一樣知道系統該做什麼。因此,把系統功能步驟以自然語言的描述方式留在 test case 層級,實作細節留在 keyword / library,並把常用的實作細節抽出來方便重複引用,就是官方推薦的使用方式。例如若要驗收從瀏覽器登入的功能,以下是一個可能的寫法:
*** Settings ***
Library Selenium2Library
Resource resource.txt # 有 Wait And Click, Wait And Input 等
# 其他 test script 也會用到的 keywords
# 每個 test case 開始前與結束後需要的步驟可寫在 Setup 與 Teardown
# 或是整個 test suite 所需的步驟可以寫在 Suite Setup/Teardown
Test Setup Proceed With Login Page
Test Teardown Close All Browsers
*** Variables ***
${HOST} http://yourhost.com
${BROWSER} chrome
${USERNAME} user
${PASSWORD} pass
${EMPTY_USERNAME} ${EMPTY}
${EMPTY_PASSWORD} ${EMPTY}
*** Test Cases ***
Valid Login
Login With Valid Credentials
Dashboard Should Be Presented
Invalid Login
Should Reject Invalid Credentials ${USERNAME} ${EMPTY_PASSWORD}
Should Reject Invalid Credentials ${EMPTY_USERNAME} ${PASSWORD}
*** Keywords ***
Proceed With Login Page
Open Browser ${HOST} ${BROWSER}
Wait Until Page Contains Welcome
Login With Valid Credentials
Login With Credentials ${USERNAME} ${PASSWORD}
Login With Credentials
[Arguments] ${uname} ${pwd}
Wait And Input id=username ${uname}
Wait And Input id=password ${pwd}
Wait And Click id=submit
Dashboard Should Be Presented
Wait Until Page Contains dashboard
Should Reject Invalid Credentials
[Arguments] ${uname} ${pwd}
Login With Credentials ${uname} ${pwd}
Wait Until Page Contains Invalid username or password
這樣寫有什麼好處呢?第一個是把 test requirement 與實作細節分開,如果只看 test case,任何人都能輕易了解第一個是在測合法登入,登入後要看到 dashboard;第二個是在測非法登入,並且分成空的密碼與空的使用者名稱兩種,只關心功能的人完全不需要知道怎麼實作。另外,盡量抽出重複的實作,如果實作細節改變了 (例如登入鈕的 id / xath 改了),就能把修改成本降到最低。很多公司完全沒有導入自動化測試,因為維護 test case 是需要成本的,而成本主要來自兩個地方:需求變動與實作細節變動。把這兩個地方拆分有助於降低維護成本。你可以想像若直接把程式邏輯翻譯在 test case 層級,當需求變動時,我們必須花時間去看這一段邏輯是在做什麼事情;若實作細節改變了,就得大改一堆 test case。所有花在了解 test case 的時間,都在消耗工程師的生產力。
這份文件與這份投影片建議了 Robot Framework 的 Do’s and Dont’s,我摘錄如下:
- Test case 的命名: Tell what, not how
- 使用變數取代 hard coding
- 適當的抽象化
- 用等的 (Wait Until…) 而不是睡的 (Sleep)
- 讓 test case 自我描述,非必要不使用 document/comment
- 盡量不要讓 test cases 有相依性
- 盡量不要在 test case 層級有 variable assignment;複雜的邏輯如迴圈等盡量放在 library
這份文件在講如何寫易維護的 test case,原則如上所述,也可以看看。
Robot Framework 與 Jenkins 的整合
與 Jenkins 的整合似乎就沒有什麼好講的了,就該裝的 plugin (robotframework, virtualenv) 裝一裝,該設定的 dependency 設一設。我目前做的事情是把一些手動測項改寫成 script,導入 Robot Framework 由 Jenkins 驅動。每當待測程式有新版的 build, 就從 git server 上把 script 拉下來, 建一個 virtualenv, 把最新版 build deploy 到機器上做 regression testing. 瀏覽器的部分在寫 script 時是用 Chrome webdriver, Jenkins 上是用 PhantomJS 跑 headless.
雖然說是自動化測試,但目前在業界還是手工藝,只能把一些簡單或常規的測項寫好之後讓它重複跑,省去 regression testing 的時間,讓 test engineer 能夠把心力放在複雜的測試上。至於真正的全自動化測試,目前還是在學術研究的階段,必須搭配自然語言處理與機器學習的進展,也是我的研究興趣。
測試的可重複性及 flaky tests
如果你曾在網路上看過程式設計師最常回答的20句話,你可能有印象其中好幾句都跟程式執行結果的不穩定性有關,例如”程式昨天還好好的”、”之前不會這樣”等等,而第一名:
“It works on my machine.”
除了讓人會心一笑之外,也點出了在軟體測試在實務上的問題:需要測試的環境組態太多,且輕微的組態差異就可能造成不同的程式行為或結果(註)。Google Testing Blog 最近的文章: Flaky Tests at Google and How We Mitigate Them 就提到了 Google 內部的情況以及他們的處理方式。這篇文章將 flaky tests 定義為 “在一樣的待測程式、待測環境及測試程式碼下,測試結果有時候 pass, 有時候 fail 的那些 test cases”,中文姑且稱之為不穩定的測試個案。不穩定的測試個案會造成什麼影響?可能會大幅降低 programmer 的生產力:
- 對於 falied test 要花時間去看錯在哪裡, 花時間 debug
- 一時之間找不到 bug, 再花時間重跑 test 看看, 結果竟然過了?!
- 若此情況發生多次, developer 對於 test 的效力就會失去信心, 以後看到 failed test 可能就直接略過 (忽略了真正的 bug), 或是多跑幾次看會不會運氣好 pass (又是時間的浪費)
因此, flaky tests 對於軟體品質跟工程師的生產力傷害甚鉅。你可能會好奇為什麼同樣的環境下測試為什麼有時候會過有時候不過?文章中提到了幾個 flaky test 的成因,例如:程式本身的行為就是不確定的 (Nondeterministic)(例如程式內會根據隨機產生的值有相對應的行為)、所用的 third party code 不穩、環境問題等等。ICSE’15 的這篇論文也提到了影響 System GUI Testing 可重複性的幾個因素:
- 執行環境,例如不同 OS,不同 browser,不同的 Java 版本,甚至只是 Oracle Java 與 OpenJDK 的不同也會有差
- 程式啟始組態與輸入檔
- 自動測試工具的設定 (以 GUI 測試來說最常見的就是每個動作的間隔時間)
- 其他無法控制的因素,例如以程式啟動的時間日期做 random seed 等
論文中也提到:就算把前三個變因都控制到一模一樣,還是無法避免程式在 code coverage 或 GUI 畫面上會出現不同的測試結果。那 flaky tests 在 Google 內部出現的情況如何?文章中提到兩個統計數據:
- 全部的測試中有 1.5% 是 flaky tests
- 在程式提交後的自動測試 (post-submit testing), CI (Continuous Integration) 系統找出的由 passed 變成 failed 的 tests 中, 有 84% 含有 flaky tests
比例不算低,而 Google 用了一些方法去對應 flaky tests:
- test 連續 fail 三次才標記為 fail (降低是 flaky test 的可能性, 但就多了執行時間)
- 對於 test 可以標記其 flakiness (我猜是人工標註), 自動把高 flakiness 的 test 放到隔離區, 日後處理, 以免影響整體測試.
- 目前正在試著從 code 或 execution traces 裡找出與 flakiness 有高度相關的 features
而上面提到的論文也建議了一些讓 System GUI Testing 可重複的一些建議步驟:
- 確保執行環境是有紀錄的,且保持一致
- 同一個 test case 跑多次再確定結果
- 注意 application specific 的要求 (例如用到執行時間做 rand seed, file/network permissions, memory 要求等)
其實可以看到目前還沒有什麼好的解決方式。
註:專門探討如何系統化測試程式的各種參數或環境組合的研究叫做 Combinatorial Testing, 這篇論文有廣泛的回顧
